
How Artificial Intelligence will finance Collective Intelligence
Anyone training an AI system as they use it should own it via a data union.
This is one of several posts exploring how a decentralised ecosystem for collective intelligence could be bootstrapped into existence.
As set out in my introductory post (above), I’m exploring these questions by re-imagining how MyHub.ai could evolve into an open-source toolkit positioned within a decentralised, self-sustaining and open-source ecosystem for collective intelligence.
The previous two posts described a “myhub toolkit”, with which Editors can build a Solid-hosted content management system (CMS) for their Hub; where the CMS is also a Tool4Thought, and helps Editors collaborate with others inside their Library via decentralised social media networking.
This post explores how AI could turbocharge these systems and finance the resulting ecosystem, providing an alternative to Big Tech AI monopolies.
Open-source ChatGPT alternatives urgently needed
As I was preparing these posts ChatGPT burst onto the scene, horrifying and delighting people in equal measure.
I actually looked into chatbots as an interface to my personal Library almost exactly 6 years ago (all three posts). I didn’t have an AI engine to play with, of course, but back then I could already imagine how a simple bot could be an efficient content discovery guide for one’s Library of notes:
“such a bot would walk users through refining their search, quickly drilling through mountains of content to find the diamond they need using no more than their thumb as they wait for a bus.”
- Boosting CuratorBots with Faceted Search
But ChatGPT does more than find content: it makes it up. By the time you read this (I hope!) you’ll have realised to not trust anything it says:
“artificial language models effectively operate via a trick mirror — learning the form of the English language without possessing any of the inherent linguistic capabilities that would demonstrate actual understanding.”
- ChatGPT, Galactica, and the Progress Trap
The awful and sometimes dangerous texts it’s producing are the inevitable result of a system being released before it’s safe. Which happened simply because it’s cheaper to make safe if you can get people to train it for free.
But Mathew, isn’t free AI training what your proposed ecosystem is based on? Yes, but with one crucial difference, as set out below: the people training the AI algorithms in this ecosystem own and benefit from them.
The alternative is to let Microsoft‘s OpenAI and other Big Tech companies own this space entirely.
Contrast that with ChatGPT’s owners OpenAI, who have released absolutely none of their research and are currently asking us to train their unsafe AI for free, in the process creating:
“a technical and business moat to keep others out… We are now facing the prospect of a significant advance in AI using methods that are not described in the scientific literature and with datasets restricted to a company that appears to be open only in name… And if history is anything to go by, we know a lack of transparency is a trigger for bad behaviour in tech spaces”
- Everyone’s having a field day with ChatGPT — but nobody knows how it actually works
Hence the urgency. Only by creating a decentralised, open-source ecosystem can we develop cooperatively-owned AI engines to benefit society as a whole. The alternative is to let Microsoft‘s OpenAI and other Big Tech companies own this space entirely.
My own personal ChatGPT
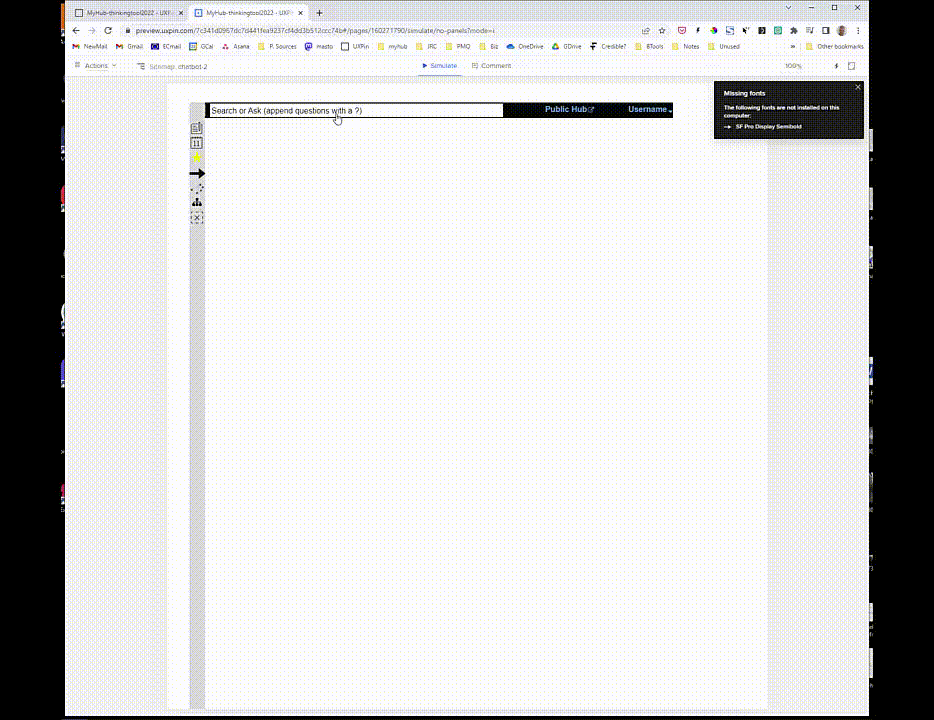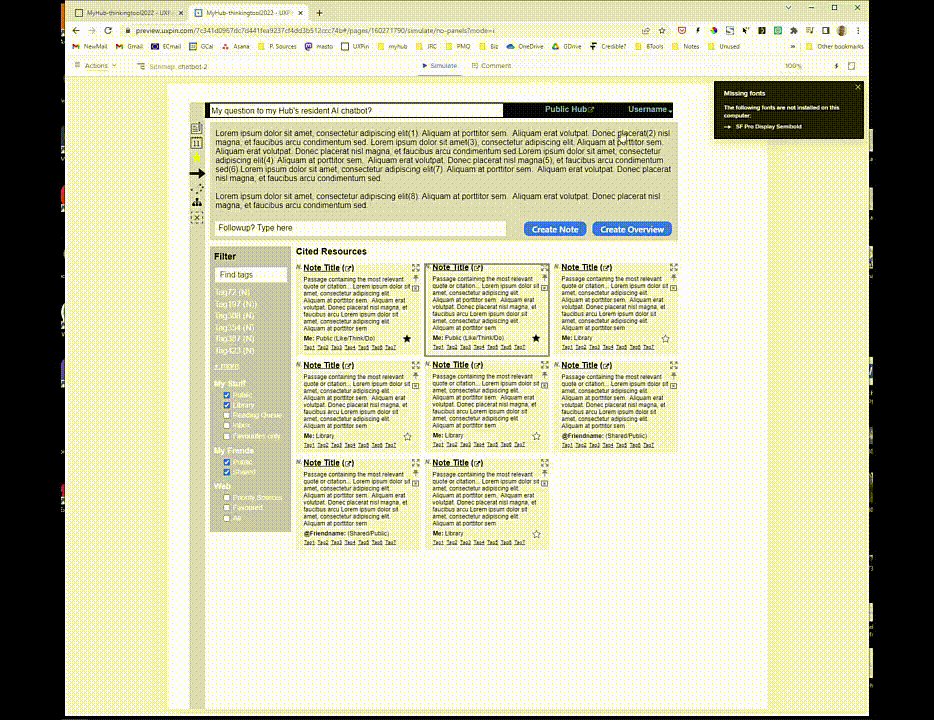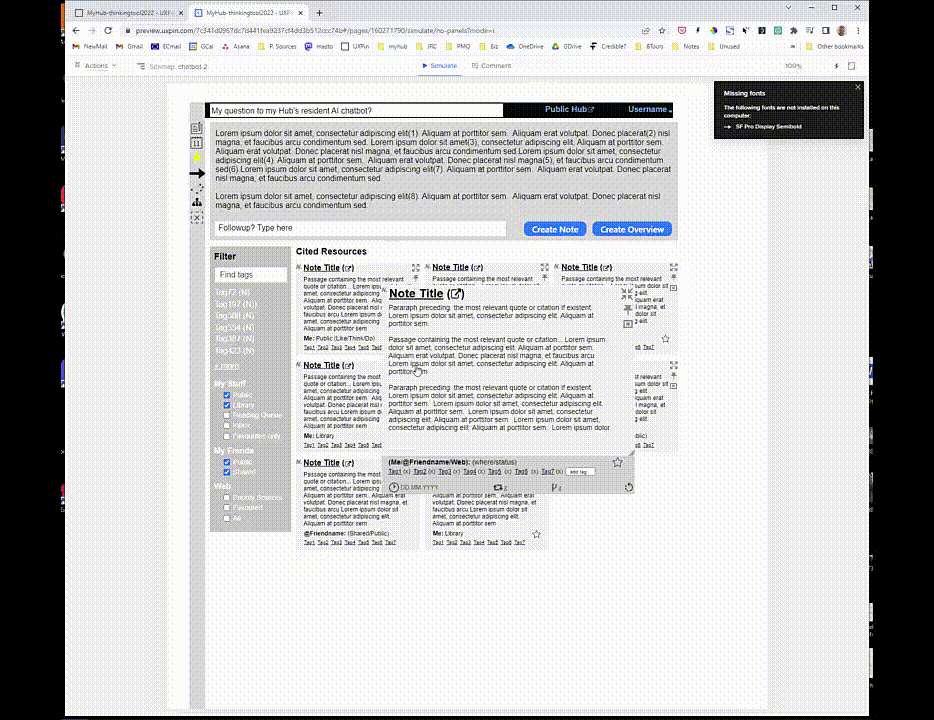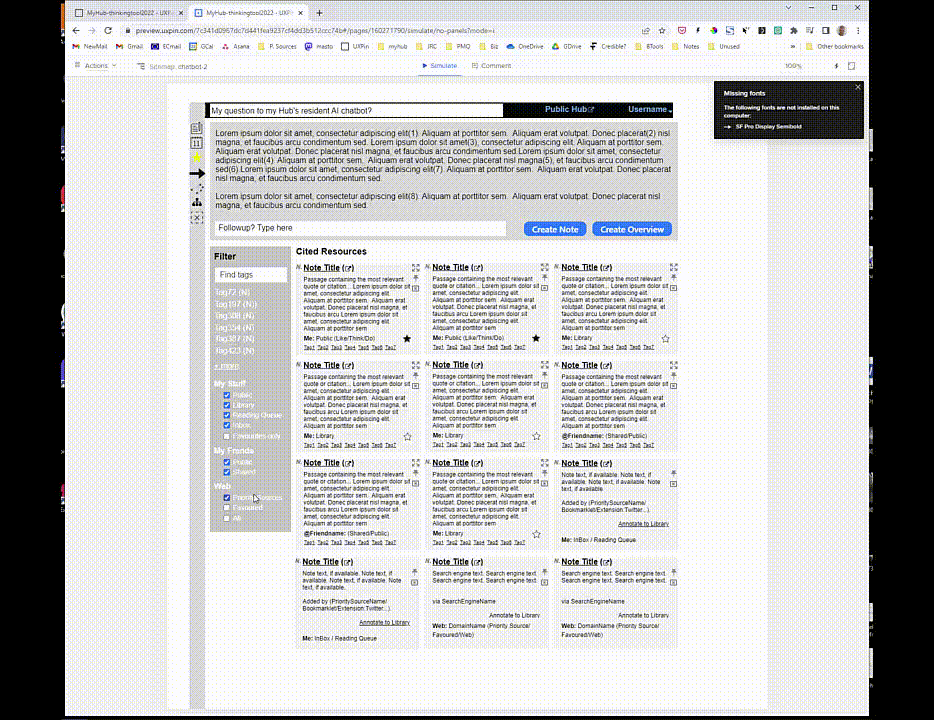
If you could access AIs from within the Tool4Thought driving your private library and public Hub or other website, what would you want?
I’ve been wanting an autoclassification servic, helping Editors organise their notes by proposing tags, for over a decade. I launched MyHub.ai in 2020 when I realised that the autoclassification algorithm could be trained not only by the Editors’ corrections but also by their visitors’ behaviour on their public sites, opening up the possibility of monetising it.
I’ve since added several more AI services to my wishlist, such as automatic semantic enrichment (describing content using linked data, not just tags), autoprompt (recommending relevant content), auto summary and even Filter Bubble Analysis and AI-powered spaced repetition. All can be trained by Editors, and some by the visitors to their public sites. I have wireframes showing these various services in action, but ChatGPT just made at least half of them irrelevant.
Editors will simply want their own personal ChatGPT.
One of the giveaways for me as I played with ChatGPT was the lack of citations in its answers. While this is something that perplexity.ai has found a partial way around, ChatGPT’s responses will always be suspect: it’s simply impossible to know what it’s inventing and what is based on actual online knowledge, and how credible that knowledge is.
Your chatbot applied to your interests, working from your notes and using content from sources you trust.
But what if you could access an AI with ChatGPT’s language abilities which provided quotes and citations to back up its response? Moreover, what if it favoured, when choosing quotes and citations, your own notes in your Library, followed by the content shared with you by your trusted Friends, then content published by your Priority Sources, and then content published by publishers you’ve annotated to your Library frequently?
Your chatbot, initially trained on huge datasets but then applied specifically to your interests, would be working from your notes, learning from your writing style and using content from sources you trust.
Revenue sources in brief
So how does this get financed? I see three classes of revenue source.
Community-trained AI as a service
I’ve wanted an auto-categorisation algorithm that learns from the human curators using it integrated into my writing and curation tools for almost a decade, but I only launched MyHub.ai to explore these ideas after realising:
- the Hub’s interface could also harness audience behaviour to train the algorithm, so both Hub Editors and their visitors could train the engine;
- such an algorithm could be monetised as a Software as a Service (SaaS), financing platform and ecosystem development.
Autoclassification, however, turned out to be the tip of an iceberg. Most of the AI services set out later can both enhance the tools described in the preceding posts and learn from the Editors’ behaviour (and in some cases their visitors’). As these AI-powered Tools4Thought get better, more people will use them, improving them further in a virtuous circle.
Highly trained algorithms are valuable. While they are provided free of charge to the data union of Editors who use them to manage their ideas and published posts, they can also be monetised as SaaS to third parties.
ecosystem populated by competing providers
Note: I am not putting forward myhub.ai as the only ‘home’ of these future AI algorithms, as that would make it a centralised node supporting a decentralised ecosystem. Instead, the ecosystem should be populated by a network of competing AI providers, each providing services via their open-source toolkits and using their tools’ uptake to refine their AI algorithms.
Premium service platform and community
There is nothing to stop Editors from downloading the myhub toolkit and setting up their Tool4Thought and public website, integrated with their own Solid Pod and Fediverse account. Such self-hosting Editors can connected to AI algorithms if they wish.
Not everyone, of course, will want to take that route, so a second revenue source exists where sites like MyHub.ai site take care of everything for the user for a small subscription fee. With a click it would roll out the basic Solid infrastructure, Tool4Thought, your choice of public website (Hub, enewsletter, blogs, collaboration workspaces, etc), subscriber management system (below) and Fediverse presence, all integrated together with the relevant AI services.
In addition to the toolkit code repository, therefore, it would also provide a template and code marketplace, support the Editors’ community, and provide an on-ramp for new users.
Premium service: subscriber revenue
As set out in Social knowledge graphs for collective intelligence, a MyHub Editor can set certain content in their Library as visible only to their Friends, or even sub-Groups of Friends.
The same feature could be turned into a Substack-style service, with the Editor providing access to not just posts but also notes, ideas, overviews and more to paying subscribers, like Nat Eliason (h/t: Marie Dolle).
Self-hosted Editors, of course, will keep 100%, but those using a premium service platform (see above) would share revenue with it.
Centralised AI, decentralised network: data unions in the DisCO?
Who would manage this, and who would benefit?
While the endgame is a decentralised ecosystem, these AI tools require massive data, which implies centralisation. How to square this circle? The starting point is to form a decentralised “data union”, of which all Editors using these AI tools are members. That means each Editor:
- benefits from these AI tools for free
- agrees to share the data required to train these tools as they use them
- cooperatively runs the SaaS in proportion to the training they provide.
As noted earlier, this chapter proposes directions for future research. Two possible directions include:
Decentralised Autonomous Organisation (DAO)
Until around a year ago, a lot of people I’ve spoken to advocated setting up a Distributed Autonomous Organisation (DAO) and its cryptocurrency for managing the platform.
“MyHub DAO” would therefore run the premium platform (above), selling its services (Solid hosting, Thinking Management System, public site templates, subscriber management, AI SaaS) for “MyHub tokens”.
However, users would also earn these tokens as they use the platform, rewarding them for the training they give the AI. Basic usage should earn enough tokens to pay for a basic template. Advanced users can also earn tokens by developing their own templates and selling them via the platform’s marketplace, and/or sell subscription services for tokens.
Tokens, of course, could also be bought using normal currency to access these services, and spent on accessing the AI-SaaS for use in the buyers’ own systems. As the quality of the algorithms improve in a virtuous circle, token value will rise.
This DAO would be able to invest this revenue in platform development, buy back value tokens to increase their value, or distribute it to tokenholders. Token holders will have a say in these decisions, proportionate to their contribution to the platform in terms of AI training, subscription revenue, etc.
Distributed Cooperative Organisation (DisCO)
An alternative approach is to set up a DisCO, or Distributed Cooperative Organisation — essentially a Distributed Autonomous Organisation without the assorted chaos surrounding speculative cryptocurrencies and NFTs.
While I include both approaches because both deserve to be considered seriously, I prefer — on the face of it - the DisCO option to avoid risking entanglement with the whole cryptocurrency sector.
Dig deeper
This post is one of a series, the “executive summary” of which is A Minimum Viable Ecosystem for collective intelligence. Others include:
- Thinking and writing in a decentralised collective intelligence ecosystem
- Social knowledge graphs for collective intelligence
- Our first pilot project: Mapping the Tools4Thought landscape using collective intelligence tools.
The above posts, finally, are “permanent versions” of their living counterparts on the Thinking Tools Map site, to which you can contribute and comment. See this post’s current version.
Follow and get in touch:
- subscribe to my newsletter,
- browse everything I #LikeThinkDo tagged “Collective Intelligence” (or grab its RSS feed)
- follow me on Mastodon, here on Medium or on Twitter (although I’m quiet quitting the latter).
